项目(projects) V3
文档说明
版本
✔️ ver_1.0.1
概述
🪐 项目模板
我们的projects repo包含多种应用于NLP任务、模型、工作流和集成的各种项目模板,这些模版都可以直接克隆和运行。最简单的方式,是选择并克隆一个模板,然后修改它!
spaCy project为你提供针对不同用例和领域的端到端的spaCy工作流程的管理和共享,并协调训练,打包并启动你自定义的管道。你可以先克隆一个预定义的项目模板,根据你的需要调整它,加载你的数据,训练一个管道,然后将其导出为Python包,最后把输出上传到远程存储并与您的团队共享您的结果。 spaCy projects可以通过一个新的spaCy project命令来使用,而且官方还提供了模板仓库。

🪐开始使用项目模板:
pipelines/tagger_parser_ud
最简单的方法是克隆一个项目模板然后运行它,例如,这个端到端模板可让你在普遍的依赖树上(Universal Dependencies treebank)训练一个part-of-speech tagger和and dependency parser。
$ python -m spacy project clone pipelines/tagger_parser_ud$ python -m spacy project clone pipelines/tagger_parser_udspaCy项目可以轻松地集成许多其他有用的工具,使你能够在数据科学和机器学习生态中追踪和管理你的数据和实验,迭代你的demo和原型并将你的模型投入生产。
| 序号 | 工具名 | 用途 | 说明 |
|---|---|---|---|
| 1 | DVC | 数据管理与版本控制工具 | |
| 2 | prodigy | 数据标记工具 | 挺贵的 |
| 3 | Streamlit | 管道的可视化和demo,能够应用python实现可视化展示 | spacy_streamlit_demo一个基于spacy-streamlit的spacy展示工程 |
| 4 | FastAPI | 一个高性能的web框架,官网,类似flask | 具有交互文档(类似swagger) |
| 5 | Ray | 分布式和并行化训练 | |
| 6 | Weights&Biases | 追踪的实验和结果 | |
| 7 | Hugging Face HUB | 上传的的管道到Hugging Face HUB服务 |
使用项目模板
1. 克隆一个项目模板
克隆
克隆一个项目,spaCy调用git并使用“sparse checkout”功能来克隆相关的目录或多个目录。
spacy project clone命令能够克隆一个现有的项目模板并将文件复制到本地目录。然后你可以运行该项目,例如:训练管道并编辑命令和脚本来构建完全自定义的工作流。
$ python -m spacy project clone pipelines/tagger_parser_ud$ python -m spacy project clone pipelines/tagger_parser_ud默认情况下,项目将被克隆到当前工作目录中。您可以指定可选的第二个参数来定义输出目录。如果您不想使用spaCy的模板工程仓库,可以--repo 参数自定义你的仓库,你还可以使用任何你有权访问的 Git存储库。
2. 获取项目资产(assets)
# project.YML
assets:
- dest: 'assets/training.spacy'
url: 'https://example.com/data.spacy'
checksum: '63373dd656daa1fd3043ce166a59474c'
- dest: 'assets/development.spacy'
git:
repo: 'https://github.com/example/repo'
branch: 'master'
path: 'path/development.spacy'
checksum: '5113dc04e03f079525edd8df3f4f39e3'# project.YML
assets:
- dest: 'assets/training.spacy'
url: 'https://example.com/data.spacy'
checksum: '63373dd656daa1fd3043ce166a59474c'
- dest: 'assets/development.spacy'
git:
repo: 'https://github.com/example/repo'
branch: 'master'
path: 'path/development.spacy'
checksum: '5113dc04e03f079525edd8df3f4f39e3'资产是您的项目需要的数据文件 — 例如,用于初始化模型的训练和评估数据或预训练向量和嵌入式向量。每个项目模板都带有一个project.yml,它定义了要下载的资产以及放置它们的位置。spacy project assets将为您获取项目资产:
$ cd some_example_project
$ python -m spacy project assets$ cd some_example_project
$ python -m spacy project assets资产链接(URL)可以是多种不同的协议:HTTP、HTTPS、FTP、SSH,甚至云存储,例如 GCS 和 S3。您还可以使用git获取资产,方法是将url字符串替换为git块(git block)。spaCy将使用Git的sparse checkout功能来避免下载整个存储库。
3. 运行命令
# project.YML
commands:
- name: preprocess
help: "Convert the input data to spaCy's format"
script:
- 'python -m spacy convert assets/train.conllu corpus/'
- 'python -m spacy convert assets/eval.conllu corpus/'
deps:
- 'assets/train.conllu'
- 'assets/eval.conllu'
outputs:
- 'corpus/train.spacy'
- 'corpus/eval.spacy'# project.YML
commands:
- name: preprocess
help: "Convert the input data to spaCy's format"
script:
- 'python -m spacy convert assets/train.conllu corpus/'
- 'python -m spacy convert assets/eval.conllu corpus/'
deps:
- 'assets/train.conllu'
- 'assets/eval.conllu'
outputs:
- 'corpus/train.spacy'
- 'corpus/eval.spacy'命令由一个或多个步骤组成,可以使用spacy project run命令运行。 以下将运行project.yml文件中定义的reprocess命令。
$ python -m spacy project run preprocess$ python -m spacy project run preprocess命令可以使用deps(命令需要的文件)和output(命令创建的文件)键(keys)来定义它们的预期依赖项和输出。这允许你的项目跟踪更改并确定一个命令是否需要重新运行。例如,如果您的输入数据发生变化,您希望重新运行(re-run)preprocess命令。但如果没有任何改变,这一步就可以跳过。您还可以设置--force来强制重新运行一个命令 或者--dry来执行一个“试运行”(dry run)并查看会发生什么(脚本不需要实际运行)
4. 运行工作流
# project.YML
workflows:
all:
- preprocess
- train
- package# project.YML
workflows:
all:
- preprocess
- train
- package工作流是一系列按顺序运行且通常相互依赖的命令。例如,要生成管道包(package),您可以先转换数据,然后运行spacy train在转换后的数据上训练您的管道,成功之后,运行spacy package将训练完成的工件转换为可安装的Python包。以下命令运行project.yml 中定义的工作流all,并按顺序执行其中指定的命令:
$ python -m spacy project run all$ python -m spacy project run all使用命令中定义的期望的dependencies and outputs,spaCy可以确定是重新运行命令(如果其输入\输出已更改)还是跳过它。如果您希望实现更高级的数据管道并在Git中跟踪您的更改,请查看Data Version Control (DVC) integration。spacy project dvc命令能够为你的project.yml文件定义的工作流生成一个DVC配置文件,以便您可以将spaCy项目作为DVC存储库进行管理。
5.(可选)推送到远程存储
project.YML
remotes:
default: 's3://my-spacy-bucket'
local: '/mnt/scratch/cache'project.YML
remotes:
default: 's3://my-spacy-bucket'
local: '/mnt/scratch/cache'管道训练完成后,您可以选择使用spacy project push命令通过S3、 Google Cloud Storage或 SSH等协议将您的输出上传到远程存储。这可以帮助您导出管道包、与团队共享工作或缓存结果以避免重复工作。
$ python -m spacy project push$ python -m spacy project pushproject.yml中的remotes部分(section)允许你为不同的存储分配名称。要从远程存储下载状态,您可以使用spacy project pull命令。有关更多详细信息,请参阅文档remote storage。
项目目录和资产
project.yml
project.yml文件定义了项目所依赖的资产,例如数据集和预训练的权重,以及一系列可以单独运行或作为工作流运行的命令——例如,预处理数据,将数据转换为spaCy的格式,训练管道,评估它并导出指标,打包它并启动一个快速的网络演示。它看起来非常类似于用于定义CI管道的配置文件。
提示:使用多行
YAML语法来表示长值YAML具有多行语法,有助于提高值的可读性,例如项目描述或带有多个参数的命令。
例如:
explosion/projects/v3/pipelines/tagger_parser_ud/explosion/projects/v3/pipelines/tagger_parser_ud/提示:在
CLI上覆盖变量 如果您想在CLI上覆盖一个或多个变量并且尚未指定项目目录,则需要添加.为占位符:
$ python -m spacy project run test . --vars.foo bar$ python -m spacy project run test . --vars.foo bar| 部分(section) | 描述 |
|---|---|
| title | 可选项目标题,用于--help消息和自动生成的文档中使用的。 |
| description | 可选项目描述,在自动生成的文档中使用。 |
| vars | 可以在路径、URLs和脚本中引用并在CLI上覆盖的字典变量,就像config.cfg variables一样。例如,${vars.name}将使用变量name的值。变量需要在 section vars中定义,业可以是嵌套的 dict,因此您可以引用${vars.model.name}。 |
| env | 字典变量,映射到运行项目时将读取的环境变量的名称。例如,${env.name}将使用定义为的环境变量的值name。 |
| directories | 可选的目录列表,项目中为资产、训练输出、指标等创建的。spaCy将确保这些目录始终存在。 |
| assets | 资产列表,可以使用project assets命令 获取。url定义一个URL或本地路径,dest是相对于项目目录的目标文件,checksum是可选的,如果文件的校验和不匹配将会引发错误。除了url,您还可以提供一个带有repo、branch、path键的git块,以从Git下载存储库。 |
| workflows | 工作流名称字典,映射到命令名称列表,按顺序执行。工作流可以使用project run命令运行。 |
| commands | 命令列表。命令可以定义可选的帮助消息(当用户在CLI中添加--help参数时显示),script,以及要运行的命令列表。deps和outputs让您分别定义命令依赖的文件和生成的文件。这让spaCy可以确定是否需要重新运行命令,因为它的依赖关系或输出发生了变化。命令还可以作为工作流的一部分运行,也可以使用project run命令分别运行。 |
| spacy_version | 可选的spaCy版本,例如项目兼容的版本范围>=3.0.0,<3.1.0。如果加载了不兼容的版本,则加载项目时会引发错误。 |
数据资产
资产是您的项目可能需要的任何文件,例如训练(train)和开发(dev)语料库或用于初始化模型的预训练权重。资产在project.yml文件的assets块中定义,并且可以使用project assets命令下载。定义校验和可以让您验证运行您的项目的其他人将使用和你相同的文件。资产URLs可以是多种不同的协议:HTTP、HTTPS、FTP、SSH,甚至是GCS和S3等云存储。当然,您也可以从Git存储库下载资产。
从URL或云存储下载
底层逻辑中,spaCy使用smart-open库,因此您可以使用它支持的任何协议。请注意,您可能需要安装额外的依赖项才能使用某些协议。
#project.YML
assets:
# Download from public HTTPS URL
- dest: 'assets/training.spacy'
url: 'https://example.com/data.spacy'
checksum: '63373dd656daa1fd3043ce166a59474c'
# Download from Google Cloud Storage bucket
- dest: 'assets/development.spacy'
url: 'gs://your-bucket/corpora'
checksum: '5113dc04e03f079525edd8df3f4f39e3'#project.YML
assets:
# Download from public HTTPS URL
- dest: 'assets/training.spacy'
url: 'https://example.com/data.spacy'
checksum: '63373dd656daa1fd3043ce166a59474c'
# Download from Google Cloud Storage bucket
- dest: 'assets/development.spacy'
url: 'gs://your-bucket/corpora'
checksum: '5113dc04e03f079525edd8df3f4f39e3'| 名称 | 描述 |
|---|---|
| dest | 将下载的资产保存到的目标路径(相对于项目目录),包括文件名。 |
| url | 要下载的URL,使用相应的协议。 |
| checksum | 文件的可选校验和。如果提供,它将用于验证文件是否匹配,如果已存在具有相同校验和的本地文件,将跳过下载。 |
| description | 可选的资产描述,用于自动生成的文档。 |
从 Git 存储库下载
如果提供了git块,则从给定的Git存储库下载资产。您可以从您有权访问的任何存储库中下载。在底层,这使用了Git的“sparse checkout”特性,所以你可以只下载你需要的文件,而不是整个repo。
#project.YML
assets:
- dest: 'assets/training.spacy'
git:
repo: 'https://github.com/example/repo'
branch: 'master'
path: 'path/training.spacy'
checksum: '63373dd656daa1fd3043ce166a59474c'
description: 'The training data (5000 examples)'#project.YML
assets:
- dest: 'assets/training.spacy'
git:
repo: 'https://github.com/example/repo'
branch: 'master'
path: 'path/training.spacy'
checksum: '63373dd656daa1fd3043ce166a59474c'
description: 'The training data (5000 examples)'| 名称 | 描述 |
|---|---|
| dest | 将下载的资产保存到的目标路径(相对于项目目录),包括文件名。 |
| git | repo:要从中下载的存储库的URL。path:要下载的文件或目录的路径,相对于repo根目录。"" 指定根目录。branch: 要下载的分支。默认为"master". |
| checksum | 文件的可选校验和。如果提供,它将用于验证文件是否匹配,如果已存在具有相同校验和的本地文件,将跳过下载。 |
| description | 可选的资产描述,用于自动生成的文档。 |
使用私有资产
#project.YML
assets:
- dest: 'assets/private_training_data.json'
checksum: '63373dd656daa1fd3043ce166a59474c'
- dest: 'assets/private_vectors.bin'
checksum: '5113dc04e03f079525edd8df3f4f39e3'#project.YML
assets:
- dest: 'assets/private_training_data.json'
checksum: '63373dd656daa1fd3043ce166a59474c'
- dest: 'assets/private_vectors.bin'
checksum: '5113dc04e03f079525edd8df3f4f39e3'对于许多项目,您使用的数据集和权重可能是在公司内部,无法通过 Internet获得。这种情况下,您可以指定目标路径和校验和,而不设置URL。当您的队友克隆并运行您的项目时,他们可以自己将文件放在相应的目录中。这project assets命令会提醒您丢失的文件和不匹配的校验和,这样您就可以确保其他人正在使用相同的数据运行您的项目。
依赖和输出
project.yml文件中定义的每个命令都可以选择定义依赖项和输出列表。这些是命令需要和创建的文件。例如,用于训练管道的命令可能依赖于一个config.cfg文件以及训练和评估数据,它会导出一个目录model-best,然后您可以在其他命令中重复使用该目录。
#project.YML
commands:
- name: train
help: 'Train a spaCy pipeline using the specified corpus and config'
script:
- 'python -m spacy train ./configs/config.cfg -o training/ --paths.train ./corpus/training.spacy --paths.dev ./corpus/evaluation.spacy'
deps:
- 'configs/config.cfg'
- 'corpus/training.spacy'
- 'corpus/evaluation.spacy'
outputs:
- 'training/model-best'#project.YML
commands:
- name: train
help: 'Train a spaCy pipeline using the specified corpus and config'
script:
- 'python -m spacy train ./configs/config.cfg -o training/ --paths.train ./corpus/training.spacy --paths.dev ./corpus/evaluation.spacy'
deps:
- 'configs/config.cfg'
- 'corpus/training.spacy'
- 'corpus/evaluation.spacy'
outputs:
- 'training/model-best'重新运行(re-running)还是直接跳过(skip)
底层实现中,spaCy使用一个project.lock锁文件来存储每个命令的详细信息,以及它的依赖项和输出及其校验和。每次运行都会更新。如果此信息有任何更改,则将重新运行该命令。否则,它将被跳过。
如果您正在运行一个命令并且它依赖的文件丢失了,spaCy将向您显示一个错误。如果命令定义了自上次运行以来未更改的依赖项和输出,则将跳过该命令。这意味着您仅在需要重新运行命令时才重新运行命令。命令也可以设置no_skip: true标记它们不应该被跳过——例如用于测试的命令。没有输出的命令一直都不会被跳过。您也可以设置--force标志来强制重新运行命令或工作流,即使他没有任何更改。
注意spacy project不会根据依赖关系和输出编译任何依赖关系图,也不会自动重新运行之前的步骤。例如,如果您只运行train,它依赖于命令preprocess创建的数据,并且这些文件丢失,spaCy将提示一个错误--并且它不会只重新运行preprocess。如果您正在寻找更高级的数据管理,请查看数据版本控制 (DVC) 集成。如果您计划将spaCy项目与DVC集成,您还可以使用outputs_no_cache代替outputs定义输出,这样输出就不会被缓存或跟踪。
文件和目录结构
project.yml文件可以定义一个需要在项目中创建的directories列表。例如,assets,training,corpus等等。spaCy将确保这些目录始终可用,这样您的命令可以写入和读取它们。项目目录还将包括使用spacy project clone命令从项目模板复制的所有文件和目录。以下是一个项目目录的示例:
project.YML
directories: ['assets', 'configs', 'corpus', 'metas', 'metrics', 'notebooks', 'packages', 'scripts', 'training']project.YML
directories: ['assets', 'configs', 'corpus', 'metas', 'metrics', 'notebooks', 'packages', 'scripts', 'training']示例项目目录
├── project.yml # the project settings
├── project.lock # lockfile that tracks inputs/outputs
├── assets/ # downloaded data assets
├── configs/ # pipeline config.cfg files used for training
├── corpus/ # output directory for training corpus
├── metas/ # pipeline meta.json templates used for packaging
├── metrics/ # output directory for evaluation metrics
├── notebooks/ # directory for Jupyter notebooks
├── packages/ # output directory for pipeline Python packages
├── scripts/ # directory for scripts, e.g. referenced in commands
├── training/ # output directory for trained pipelines
└── ... # any other files, like a requirements.txt etc.├── project.yml # the project settings
├── project.lock # lockfile that tracks inputs/outputs
├── assets/ # downloaded data assets
├── configs/ # pipeline config.cfg files used for training
├── corpus/ # output directory for training corpus
├── metas/ # pipeline meta.json templates used for packaging
├── metrics/ # output directory for evaluation metrics
├── notebooks/ # directory for Jupyter notebooks
├── packages/ # output directory for pipeline Python packages
├── scripts/ # directory for scripts, e.g. referenced in commands
├── training/ # output directory for trained pipelines
└── ... # any other files, like a requirements.txt etc.如果您不希望项目创建目录,则可以将其删除并从project.yml文件中删除其条目--只需确保任何命令都不需要它。自定义模板可以使用他们需要的任何目录——只用project.yml是项目必需的文件。
自定义脚本和项目
project.yml文件允许您定义任何自定义命令并将它们作为训练、评估或部署工作流程的一部分运行。其中script部分按顺序定义了一个在子进程中调用的命令列表。这使您可以执行其他Python脚本或命令行工具。假设您编写了一些集成测试,它们加载了训练命令生成的最佳模型并检查它是否正常工作。您现在可以定义一个test命令来调用pytest、运行您的测试并使用pytest-html导出测试报告:
#project.YML
commands:
- name: test
help: 'Test the trained pipeline'
script:
- 'pip install pytest pytest-html'
- 'python -m pytest ./scripts/tests --html=metrics/test-report.html'
deps:
- 'training/model-best'
outputs:
- 'metrics/test-report.html'
no_skip: true#project.YML
commands:
- name: test
help: 'Test the trained pipeline'
script:
- 'pip install pytest pytest-html'
- 'python -m pytest ./scripts/tests --html=metrics/test-report.html'
deps:
- 'training/model-best'
outputs:
- 'metrics/test-report.html'
no_skip: true将training/model-best添加到命令的deps可让您确保文件可用。如果文件不可用,spaCy将显示错误并且命令不会运行。设置no_skip: true意味着命令将始终运行,即使依赖项(经过训练的管道)没有改变。这在这里很有意义,因为您通常不想跳过测试。
编写自定义脚本
本质上您的项目可以将命令行运行的任何内容编辑为自定义脚本。这是一个自定义脚本的示例,它使用typer快速简便的构建命令行参数,您可以通过以下方式定义project.yml:
关于
typertyper是一个使用类型提示构建Python CLI的现代库。它是spaCy的依赖项,因此它已经预先安装在您的环境中。函数参数自动成为CLI位置参数,并且使用Python类型提示定义值类型。例如,batch_size: int表示将通过命令行提供的值转换为整数。
# SCRIPTS/CUSTOM_EVALUATION.PY
import typer
def custom_evaluation(batch_size: int = 128, model_path: str, data_path: str):
# The arguments are now available as positional CLI arguments
print(batch_size, model_path, data_path)
if __name__ == "__main__":
typer.run(custom_evaluation)# SCRIPTS/CUSTOM_EVALUATION.PY
import typer
def custom_evaluation(batch_size: int = 128, model_path: str, data_path: str):
# The arguments are now available as positional CLI arguments
print(batch_size, model_path, data_path)
if __name__ == "__main__":
typer.run(custom_evaluation)在您的project.yml文件中,您可以运行带有参数的脚本python scripts/custom_evaluation.py。您还可以定义vars部分,然后在命令、路径和URLs中替换可重用变量。在此示例中,批量大小被定义为变量并通过${vars.batch_size}添加到脚本中。就像在训练配置中一样,您也可以在命令行上覆盖设置——例如使用--vars.batch_size。
CALLING INTO PYTHON
如果您的任何命令脚本调用到python,spaCy将负责将其替换为您的sys.executable,以确保您使用相同的Python(而不是系统上安装的其他Python)执行所有操作。它还标准化对python3和pip3和pip的引用。
# PROJECT.YML
vars:
batch_size: 128
commands:
- name: evaluate
script:
- 'python scripts/custom_evaluation.py ${vars.batch_size} ./training/model-best ./corpus/eval.json'
deps:
- 'training/model-best'
- 'corpus/eval.json'# PROJECT.YML
vars:
batch_size: 128
commands:
- name: evaluate
script:
- 'python scripts/custom_evaluation.py ${vars.batch_size} ./training/model-best ./corpus/eval.json'
deps:
- 'training/model-best'
- 'corpus/eval.json'您还可以使用env部分来引用环境变量并使它们的值可用于命令。这对于覆盖命令行上的设置和传递系统级设置很有用。
使用示例
export GPU_ID=1 BATCH_SIZE=128 python -m spacy project run evaluate
``` yaml
PROJECT.YML
env:
batch_size: BATCH_SIZE
gpu_id: GPU_ID
commands:
- name: evaluate
script:
- 'python scripts/custom_evaluation.py ${env.batch_size}'``` yaml
PROJECT.YML
env:
batch_size: BATCH_SIZE
gpu_id: GPU_ID
commands:
- name: evaluate
script:
- 'python scripts/custom_evaluation.py ${env.batch_size}'记录(Documenting)您的项目
Readme文件示例 有关更多示例,请参阅
projects repo。

当您的自定义项目准备就绪并且您想与他人共享时,您可以使用spacy project document命令来自动生成一个好看的、markdown格式的README文件,该文件会根据project.yml文件构建。它将列出项目中定义的所有命令、工作流和资产,并包含如何运行项目的详细信息,以及相关spaCy文档的链接,以方便其他人能够使用您的项目。
python -m spacy project document --output README.mdpython -m spacy project document --output README.md底层逻辑是,添加了隐藏标记以识别自动生成内容的开始和结束位置。这意味着您可以在其之前或之后添加自己的自定义内容,并且重新运行project document命令只会更新自动生成的部分。这使您可以轻松地保持文档最新。
请注意,如果没有找到现有的自动生成的文档,现有文件的内容将被替换。如果您希望
spaCy忽略文件而不更新它,您可以在文件的任意位置添加<!-- SPACY PROJECT: IGNORE -->标记。
从你自己的仓库克隆
spacy project clone命令允许您使用--repo选项自定义要克隆的存储库。它调用git,因此您将能够从您有权访问的任何存储库中克隆,包括私有存储库。
python -m spacy project clone your_project --repo https://github.com/you/repopython -m spacy project clone your_project --repo https://github.com/you/repo一个有效的项目模板至少需要包含一个project.yml文件。它还可以包含其他文件,例如自定义脚本、 requirements.txt列出其他依赖项、训练配置和模型元模板,或带有使用示例的Jupyter笔记本。
关于资产的重要说明 将大型数据资产、经过训练的管道或其他工件存储在
Git存储库中通常不是一个好主意,您应该通过添加一个.gitignore来排除她们. 如果要对数据和模型进行版本控制,请查看与spaCy项目集成的数据版本控制(DVC)。
远程存储
您可以使用project push命令将你的项目输出持久化到远程存储。这可以帮助您导出 管道包、与团队共享工作或缓存结果以避免重复工作。project pull命令将下载远程存储中的文件,这些文件在本地不存在或不可用。
你可以在project.yml的remotes部分定义一个或者多个远程仓库,具体是通过将字符串名称映射到存储的URL中。在底层实现中,spaCy使用smart-open库与远程存储进行通信,因此您可以使用任何支持smart-open的协议,包括S3、 Google Cloud Storage、SSH等,当然您可能需要安装额外的依赖项才能使用某些协议。
# 例子
$ python -m spacy project pull local# 例子
$ python -m spacy project pull local# PROJECT.YML
remotes:
default: 's3://my-spacy-bucket'
local: '/mnt/scratch/cache'
stuff: 'ssh://myserver.example.com/whatever'# PROJECT.YML
remotes:
default: 's3://my-spacy-bucket'
local: '/mnt/scratch/cache'
stuff: 'ssh://myserver.example.com/whatever'💡它是如何工作的
在远程存储内部,spaCy使用巧妙的目录结构来避免覆盖文件。目录结构的顶层是输出路径的URL编码版本号。在这个目录中是根据命令字符串的散列和命令的依赖项的哈希值来命名子目录。最后,目录中是文件,根据其内容的MD5值命名。
└── urlencoded_file_path # Path of original file
├── some_command_hash # Hash of command you ran
│ ├── some_content_hash # Hash of file content
│ └── another_content_hash
└── another_command_hash
└── third_content_hash└── urlencoded_file_path # Path of original file
├── some_command_hash # Hash of command you ran
│ ├── some_content_hash # Hash of file content
│ └── another_content_hash
└── another_command_hash
└── third_content_hash假设您的project.yml文件中有以下命令:
# PROJECT.YML
- name: train
help: 'Train a spaCy pipeline using the specified corpus and config'
script:
- 'spacy train ./config.cfg --output training/'
deps:
- 'corpus/train'
- 'corpus/dev'
- 'config.cfg'
outputs:
- 'training/model-best'# PROJECT.YML
- name: train
help: 'Train a spaCy pipeline using the specified corpus and config'
script:
- 'spacy train ./config.cfg --output training/'
deps:
- 'corpus/train'
- 'corpus/dev'
- 'config.cfg'
outputs:
- 'training/model-best'# 例子
└── s3://my-spacy-bucket/training%2Fmodel-best
└── 1d8cb33a06cc345ad3761c6050934a1b
└── d8e20c3537a084c5c10d95899fe0b1ff# 例子
└── s3://my-spacy-bucket/training%2Fmodel-best
└── 1d8cb33a06cc345ad3761c6050934a1b
└── d8e20c3537a084c5c10d95899fe0b1ff当你训练结束后,执行project push确保training/model-best输出保存到远程存储。然后spaCy将根据您的命令脚本和列出的依赖项(corpus/train以corpus/dev识别config.cfg)构造一个哈希, 来确定输出的执行上下文。然后它将计算training/model-best目录的MD5散列,并使用这三个信息来构造存储URL。
python -m spacy project run train
python -m spacy project pushpython -m spacy project run train
python -m spacy project push如果您更改命令或任意依赖项(例如,通过编辑config.cfg文件来调整超参数),将计算不同的创建哈希,因此当您使用project push时就不会覆盖你以前的文件。该系统甚至支持同一文件和同一上下文的多个输出。如果您的训练过程不确定,或者您具有命令中未表示的依赖项,则可能会产生这种情况。
综上所述,spacy project远程存储旨在进行一组特定的权衡。优先考虑方便、 正确和避免数据丢失。您可以随意使用project push,因为您永远不会覆盖远程状态,并且您不必担心名称或版本号。同时,您可以自行管理远程存储的大小,并删除与您不再相关的文件。
集成
数据版本控制 (Data Version Control,DVC)
概述
训练语料库或预训练权重等数据资产是任何NLP项目的核心,但它们通常难以管理:您不能只将它们检入Git存储库以进行版本化并跟踪它们。如果您有多个相互依赖的步骤,例如生成训练数据的预处理步骤,您需要确保数据始终是最新的,并且为了安全每次都需要重新运行流程的所有步骤。
数据版本控制(DVC) 是一个独立的开源工具,它可以像Git一样集成到您的工作流程中,为您的数据管道构建依赖关系图,并跟踪和缓存您的数据文件。如果您从外部源(例如存储桶,storage bucket)下载数据,DVC能够判断资源是否已更改。它还可以根据其输入是否已更改来确定是否重新运行一个步骤。所有元数据都可以存入Git存储库,因此您将始终能够重现您的实验。
数据科学团队面临围绕数据版本和机器学习模型的数据管理问题。我们如何一起跟踪数据、源代码和ML模型的变化?组织和存储这些文件和目录的变体的最佳方式是什么?
 数据非常复杂
数据非常复杂
数据科学项目的指数复杂度
该领域的另一个问题与簿记有关:能够识别过去的数据输入和流程以了解其结果、知识共享或调试。
数据版本控制(DVC)允许您在Git commits中捕获数据和模型的版本,同时将它们存储在本地或云存储中。它还提供了一种在这些不同数据内容之间切换的机制。结果是您可以遍历的数据、代码和 ML 模型的单一历史记录——您工作的正确日志!
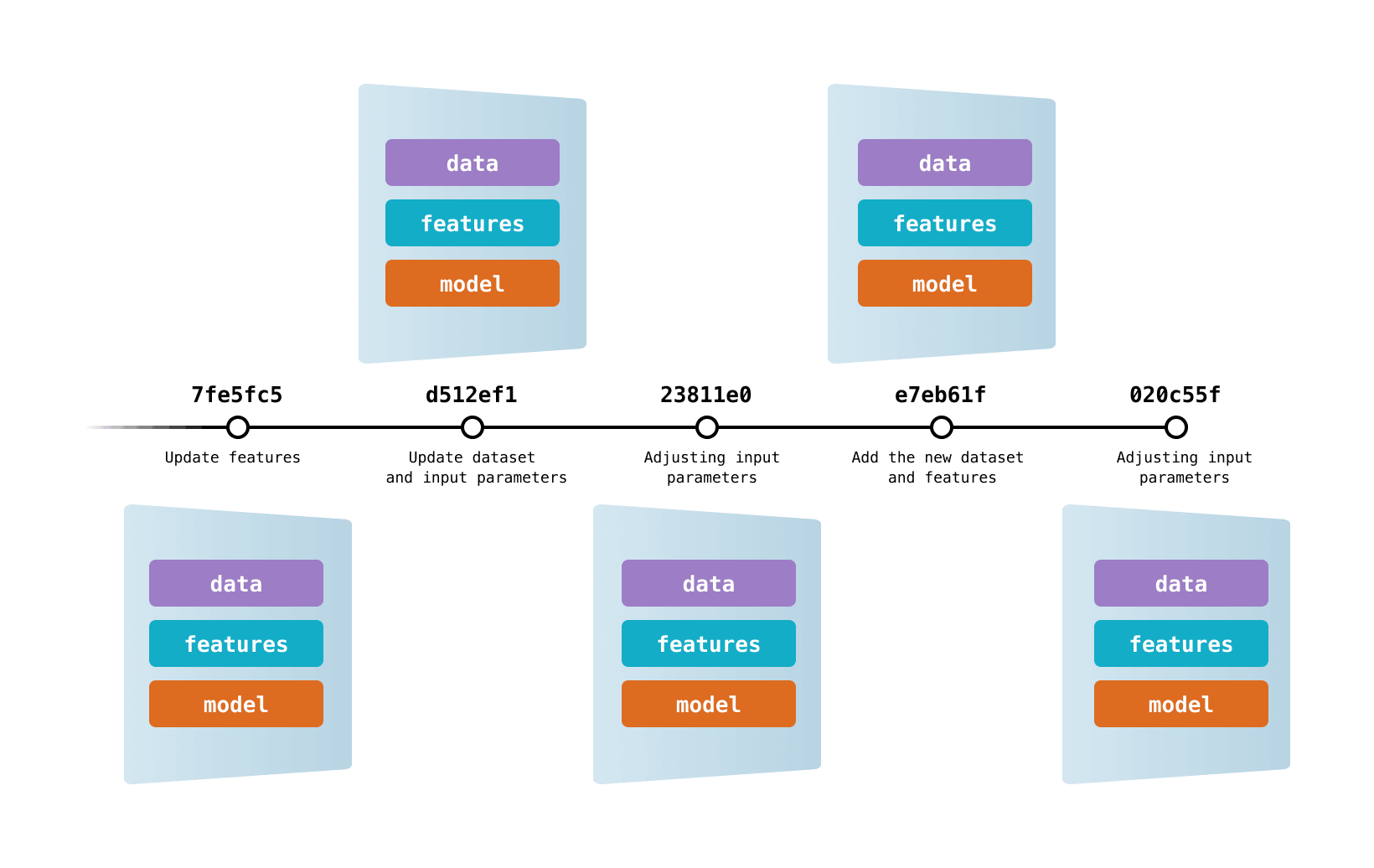
DVC为您匹配正确版本的数据、代码和模型 💘。
DVC通过编码实现数据版本控制。你只需要为需要跟踪的数据集、ML 工件等生成一次简单的元数据。这个元数据可以放在Git中代替大文件。现在,您可以使用DVC创建数据快照、恢复以前的版本、 重现实验、记录不断变化 的指标等等!
👩💻 感兴趣吗?试试我们的版本控制教程 ,那么我们简单的DVC是什么。
当您使用DVC时,您的数据文件和目录的唯一版本会 以系统的方式缓存 (防止文件重复)。工作数据存储独立于你的项目,通过DVC自动处理的文件链接保持连接,这样能够保持项目的轻巧。
方案的好处包括以下几点:
一致性:使用稳定的文件名使您的项目保持可读性——它们不需要更改,因为它们代表可变数据。不需要复杂的路径,例如
data/20190922/labels_v7_final或在源代码中不断编辑这些路径。高效的数据管理:为您的数据和模型使用熟悉且经济高效的存储解决方案(例如 SFTP、S3、HDFS 等)——不受 Git 托管 限制。DVC优化了大文件的存储和传输。
数据合规性:审查数据修改尝试作为 Git 拉取请求。审核项目的不可变历史以了解数据集或模型何时获得批准以及原因。
GitOps:将您的数据科学项目与
Git驱动的宇宙连接起来。Git工作流为高级CI/CD工具(如CML)、数据注册表等专业模式以及其他最佳实践打开了大门。
总之,数据科学和机器学习是迭代过程,其中数据、模型和代码的生命周期以不同的速度发生。DVC可帮助您管理和执行它们。
而这仅仅是个开始。DVC支持多种开箱即用的高级功能:构建、运行和数据管道的版本控制、 有效管理实验等等。
教程
Tutorial: Data and Model Versioning
使用DVC
要设置DVC,请安装相关包并将您的spaCy项目初始化为Git和DVC存储库。您还可以自定义您的DVC安装,以包括对远程存储的支持,如Google Cloud Storage、S3、Azure、SSH等。
$ pip install dvc # Install DVC
$ git init # Initialize a Git repo
$ dvc init # Initialize a DVC project$ pip install dvc # Install DVC
$ git init # Initialize a Git repo
$ dvc init # Initialize a DVC project关于隐私的重要说明
DVC默认启用使用情况分析,因此如果您在对隐私敏感的环境中工作,请务必 手动选择退出。
这spacy project dvc命令根据你的project.yml文件中的工作流创建一个dvc.yaml文件。每当您更新项目时,您都可以重新运行该命令来更新您的DVC配置。然后,您可以像管理任何其他DVC项目一样管理您的spaCy项目,运行dvc add以添加和跟踪资产,dvc repro复现工作流程或单个命令。
$ python -m spacy project dvc workflow_name$ python -m spacy project dvc workflow_name多个工作流的重要说明
每个DVC项目期望一个工作流,因此在创建配置时spacy project dvc,您需要在您的project.yml文件中指定工作流的名称. 您也可以使用多个工作流,但DVC只能跟踪一个工作流。
Prodigy(待完成)
Prodigy是我们开发的为机器学习模型创建训练数据的标注工具。它提供开箱即用的spaCy集成,并针对各种NLP任务提供了许多不同的标注方案,在循环中有和没有模型。如果Prodigy安装在您的项目中,您可以从project.yml文件中启动您的标注服务器,在数据开发和训练之间的紧密反馈循环。
Streamlit
Streamlit是一个用来构建交互式数据应用程序的Python框架。spacy-streamlit包能够帮助你快速集成spaCy可视化到你的Streamlit应用程序中,并快速启动演示以交互方式探索您的spaCy管道。它包括一个完整的嵌入式可视化工具,以及单独的组件。
#安装
$ pip install spacy-streamlit --pre#安装
$ pip install spacy-streamlit --pre
使用spacy-streamlit过程中,你可以轻松的定义脚本来启动交互式的可视化工具,这里你可以个选择使用你训练的最新的管道或者挑选你需要的管道,这样你就可以比较她们的输出结果。
🪐开始使用项目模板:
integrations/streamlit通过我们的项目模板开始使用spaCy和Streamlit。它包括一个用于启动自定义可视化器的脚本和您可以调整以展示和探索您自己的自定义训练管道的命令。
$ python -m spacy project clone integrations/streamlit$ python -m spacy project clone integrations/streamlit#示例用法
$ python -m spacy project run visualize#示例用法
$ python -m spacy project run visualize# PROJECT.YML
commands:
- name: visualize
help: "Visualize the pipeline's output interactively using Streamlit"
script:
- 'streamlit run ./scripts/visualize.py ./training/model-best "I like Adidas shoes."'
deps:
- "training/model-best"# PROJECT.YML
commands:
- name: visualize
help: "Visualize the pipeline's output interactively using Streamlit"
script:
- 'streamlit run ./scripts/visualize.py ./training/model-best "I like Adidas shoes."'
deps:
- "training/model-best"以下脚本调用project.yml并采用两个位置命令行参数:一个逗号分隔的列表用于加载管道的路径或包,以及一个示例文本作为默认文本。
explosion/projects/v3/integrations/streamlit/scripts/visualize.py
FastAPI
FastAPI是一个基于Python类型提示用于构建REST API的现代高性能框架。它已成为服务于机器学习模型的流行库,您可以在spaCy项目中使用它来快速提供经过训练的管道并向外提供REST API接口。
🪐开始使用项目模板:
integrations/fastapi通过我们的项目模板开始使用spaCy和FastAPI。它包括一个用于处理批量文本的简单REST API,以及如何从Python和JavaScript(Vanilla JS和React)查询API的使用示例。
$ python -m spacy project clone integrations/fastapi$ python -m spacy project clone integrations/fastapi#示例用法
python -m spacy project run serve#示例用法
python -m spacy project run serve# PROJECT.YML
- name: "serve"
help: "Serve the models via a FastAPI REST API using the given host and port"
script:
- "uvicorn scripts.main:app --reload --host 127.0.0.1 --port 5000"
deps:
- "scripts/main.py"
no_skip: true# PROJECT.YML
- name: "serve"
help: "Serve the models via a FastAPI REST API using the given host and port"
script:
- "uvicorn scripts.main:app --reload --host 127.0.0.1 --port 5000"
deps:
- "scripts/main.py"
no_skip: true模板中的脚本显示了一个简单的REST API,其POST端点接受批量的文本并返回批量的预测,例如在文档中找到的命名实体。输入提示和pydantic用于定义预期的数据类型。
explosion/projects/v3/integrations/fastapi/scripts/main.pyexplosion/projects/v3/integrations/fastapi/scripts/main.py
pydantic是什么?
使用python类型注释的数据验证和设置管理。pydantic在运行时强制执行类型提示,并在数据无效时提供用户友好的错误。 pydantic库是一种常用的用于数据接口schema定义与检查的库。 通过pydantic库,我们可以更为规范地定义和使用数据接口,这对于大型项目的开发将会更为友好。 Python笔记:Pydantic库简介
Ray
安装
$ pip install -U spacy[ray]
# Check that the CLI is registered
python -m spacy ray --help安装
$ pip install -U spacy[ray]
# Check that the CLI is registered
python -m spacy ray --helpRay是一个用于构建和运行 分布式应用程序的快速而简单的框架。你可以使用一个轻量级的spacy-ray扩展包通过Ray使用spaCy进行并行和分布式训练。如果扩展包和spaCy安装在同一个环境中,那么系统会自动添加spacy ray到你的spaCy CLI中。有关并行训练的更多详细信息,请参阅并行训练的使用指南 。
🪐开始使用项目模板:
integrations/ray使用我们的项目模板开始并行训练。它在Universal Dependencies Treebank上训练一个简单的模型,并允许您使用Ray并行化训练。
$ python -m spacy project clone integrations/ray$ python -m spacy project clone integrations/ray你可以在project.yml文件中整合spacy ray train,就像整合常规训练命令一样,并传递配置,以及可选的输出目录或远程存储URL和配置覆盖(如果需要)。
# PROJECT.YML
commands:
- name: "ray"
help: "Train a model via parallel training with Ray"
script:
- "python -m spacy ray train configs/config.cfg -o training/ --paths.train corpus/train.spacy --paths.dev corpus/dev.spacy"
deps:
- "corpus/train.spacy"
- "corpus/dev.spacy"
outputs:
- "training/model-best"# PROJECT.YML
commands:
- name: "ray"
help: "Train a model via parallel training with Ray"
script:
- "python -m spacy ray train configs/config.cfg -o training/ --paths.train corpus/train.spacy --paths.dev corpus/dev.spacy"
deps:
- "corpus/train.spacy"
- "corpus/dev.spacy"
outputs:
- "training/model-best"Weights & Biases
Weights & Biases是一个流行的实验跟踪平台。spaCy通过WandbLogger以开箱即用的方式集成,您可以将其添加为训练配置的[training.logger]块。然后将每个步骤的结果连同完整的训练配置一起记录到您的项目中。这意味着每个超参数、注册的函数名称和参数都将被追踪,这样您能够看到它们对结果的影响。
# 示例配置
[training.logger]
@loggers = "spacy.WandbLogger.v3"
project_name = "monitor_spacy_training"
remove_config_values = ["paths.train", "paths.dev", "corpora.train.path", "corpora.dev.path"]
log_dataset_dir = "corpus"
model_log_interval = 1000# 示例配置
[training.logger]
@loggers = "spacy.WandbLogger.v3"
project_name = "monitor_spacy_training"
remove_config_values = ["paths.train", "paths.dev", "corpora.train.path", "corpora.dev.path"]
log_dataset_dir = "corpus"
model_log_interval = 1000

🪐开始使用项目模板:
integrations/wandb </>
开始使用我们的项目模板利用权重和偏差中跟踪您的spaCy训练运行。它在IMDB电影评论数据集上训练,包含一个内置WandbLogger的简单配置,以及一个为简单的超参数网格搜索和记录结果创建配置变体的自定义示例。
$ python -m spacy project clone integrations/wandb$ python -m spacy project clone integrations/wandbHugging Face Hub
Hugging Face Hub允许您上传模型并与他人共享。它将模型托管为基于Git的存储库,这些存储空间是可以包含所有文件的存储空间。它支持开箱即用的版本控制、分支和自定义元数据,并提供基于浏览器的可视化工具以交互式地探索您的模型,以及用于生产使用的API。如果已安装spacy-huggingface-hub, 就会自动将huggingface-hub命令添加到您的spacy CLI。
#安装
pip install spacy-huggingface-hub
# Check that the CLI is registered
python -m spacy huggingface-hub --help#安装
pip install spacy-huggingface-hub
# Check that the CLI is registered
python -m spacy huggingface-hub --help然后,您可以上传任何使用spacy package打包的管道。确保设置--build wheel来输出二进制.whl文件。上传者将从管道包中读取所有元数据,包括自动生成的漂亮README.md和meta.json文件. 例如,查看我们上传的spaCy 管道。
$ huggingface-cli login
$ python -m spacy package ./en_ner_fashion ./output --build wheel
$ cd ./output/en_ner_fashion-0.0.0/dist
$ python -m spacy huggingface-hub push en_ner_fashion-0.0.0-py3-none-any.whl$ huggingface-cli login
$ python -m spacy package ./en_ner_fashion ./output --build wheel
$ cd ./output/en_ner_fashion-0.0.0/dist
$ python -m spacy huggingface-hub push en_ner_fashion-0.0.0-py3-none-any.whl上传后,您将看到管道包的实时URL,以及您可以通过pip install命令安装的wheel格式的模型文件。您还可以使用浏览器交互地测试您的管道:

在您的project.yml文件中,您可以添加一个命令,将经过训练和打包的管道上传到hub中。您可以手动运行该步骤,也可以作为工作流的一部分自动运行。确保在运行spacy package命令为您的管道包构建轮(.wheel)文件时,--build wheel参数已经被设置。
# PROJECT.YML
- name: "push_to_hub"
help: "Upload the trained model to the Hugging Face Hub"
script:
- "python -m spacy huggingface-hub push packages/en_${vars.name}-${vars.version}/dist/en_${vars.name}-${vars.version}-py3-none-any.whl"
deps:
- "packages/en_${vars.name}-${vars.version}/dist/en_${vars.name}-${vars.version}-py3-none-any.whl"# PROJECT.YML
- name: "push_to_hub"
help: "Upload the trained model to the Hugging Face Hub"
script:
- "python -m spacy huggingface-hub push packages/en_${vars.name}-${vars.version}/dist/en_${vars.name}-${vars.version}-py3-none-any.whl"
deps:
- "packages/en_${vars.name}-${vars.version}/dist/en_${vars.name}-${vars.version}-py3-none-any.whl"🪐开始使用项目模板:
integrations/huggingface_hub </>该模板将您的模型上传到Hugging Face中心。它训练并打包一个简单的管道,并在打包模型发生更改时上传。这使得端到端部署模型变得容易。
$ python -m spacy project clone integrations/huggingface_hub$ python -m spacy project clone integrations/huggingface_hubbrat
一个开源的标注工具,与Prodigy功能相同。 我们可以直接使用在线标注工具(username: "crunchy", password: "frog") 我们还可以在本地部署自己的标注服务。